13 Clustering
Every day, we interact with systems that organize vast amounts of data without explicit instructions. How does Netflix recommend movies tailored to your taste? How does Amazon categorize millions of products? These are real-world examples of clustering, a machine learning technique that groups similar items based on shared characteristics—without any predefined labels.
In many real-world scenarios, we deal with large datasets where the structure is unknown. Unlike classification, which assigns predefined labels to data points (e.g., distinguishing between spam and non-spam emails), clustering is exploratory—it helps uncover hidden patterns, making it a powerful tool for knowledge discovery. By identifying meaningful groups, clustering allows us to make sense of complex data and extract valuable insights.
Clustering is widely used across multiple domains, including:
-
Customer segmentation – Identifying distinct customer groups to personalize marketing campaigns.
-
Market research – Understanding consumer behavior to enhance product recommendations.
-
Fraud detection – Detecting suspicious financial transactions that may indicate fraudulent activity.
-
Document organization – Automatically grouping large collections of text into meaningful categories.
- Bioinformatics – Clustering genes with similar expression patterns to uncover biological insights.
This chapter provides a comprehensive introduction to clustering, covering:
- The fundamental principles of clustering and how it differs from classification.
- The mechanics of clustering algorithms and how they define similarity.
-
K-means clustering, one of the most widely used clustering techniques.
- A practical case study: segmenting cereal brands based on their nutritional content.
By the end of this chapter, you will understand how clustering works, when to apply it, and how to implement it in real-world scenarios. Let’s dive in!
13.1 What is Cluster Analysis?
Clustering is an unsupervised machine learning technique that groups data points into clusters based on their similarity. Unlike supervised learning, where models learn from labeled examples, clustering is exploratory—it uncovers hidden structures in data without predefined labels. The goal is to form groups where data points within the same cluster are highly similar, while those in different clusters are distinct.
But how does a computer determine which data points belong together? Clustering relies on similarity measures that quantify how close or distant two points are. One of the most commonly used approaches is distance metrics, such as Euclidean distance, defined as:
\[ \text{dist}(x, y) = \sqrt{ \sum_{i=1}^n (x_i - y_i)^2} \]
where \(x = (x_1, x_2, \ldots, x_n)\) and \(y = (y_1, y_2, \ldots, y_n)\) represent two data points with \(n\) features. The closer the two points, the more similar they are.
However, Euclidean distance is not always appropriate. For categorical variables, alternative strategies such as one-hot encoding transform categories into numerical values, enabling distance-based clustering. Additionally, features often require scaling (e.g., min-max normalization) to ensure that no single variable dominates the clustering process.
Clustering is often compared to classification, but they serve different purposes. Classification assigns predefined labels to new data points based on past examples, whereas clustering discovers groupings from raw data. Classification is typically used for prediction, while clustering is primarily for exploration and pattern discovery. Because clustering generates labels rather than predicting existing ones, it is sometimes referred to as unsupervised classification. These cluster assignments can then be used as inputs for further analysis, such as refining predictions in a neural network or decision tree model.
All clustering algorithms aim to achieve high intra-cluster similarity (data points within a cluster are close together) and low inter-cluster similarity (clusters are well separated). This concept is visually illustrated in Figure 13.1, where effective clusters minimize internal variation while maximizing separation between groups.
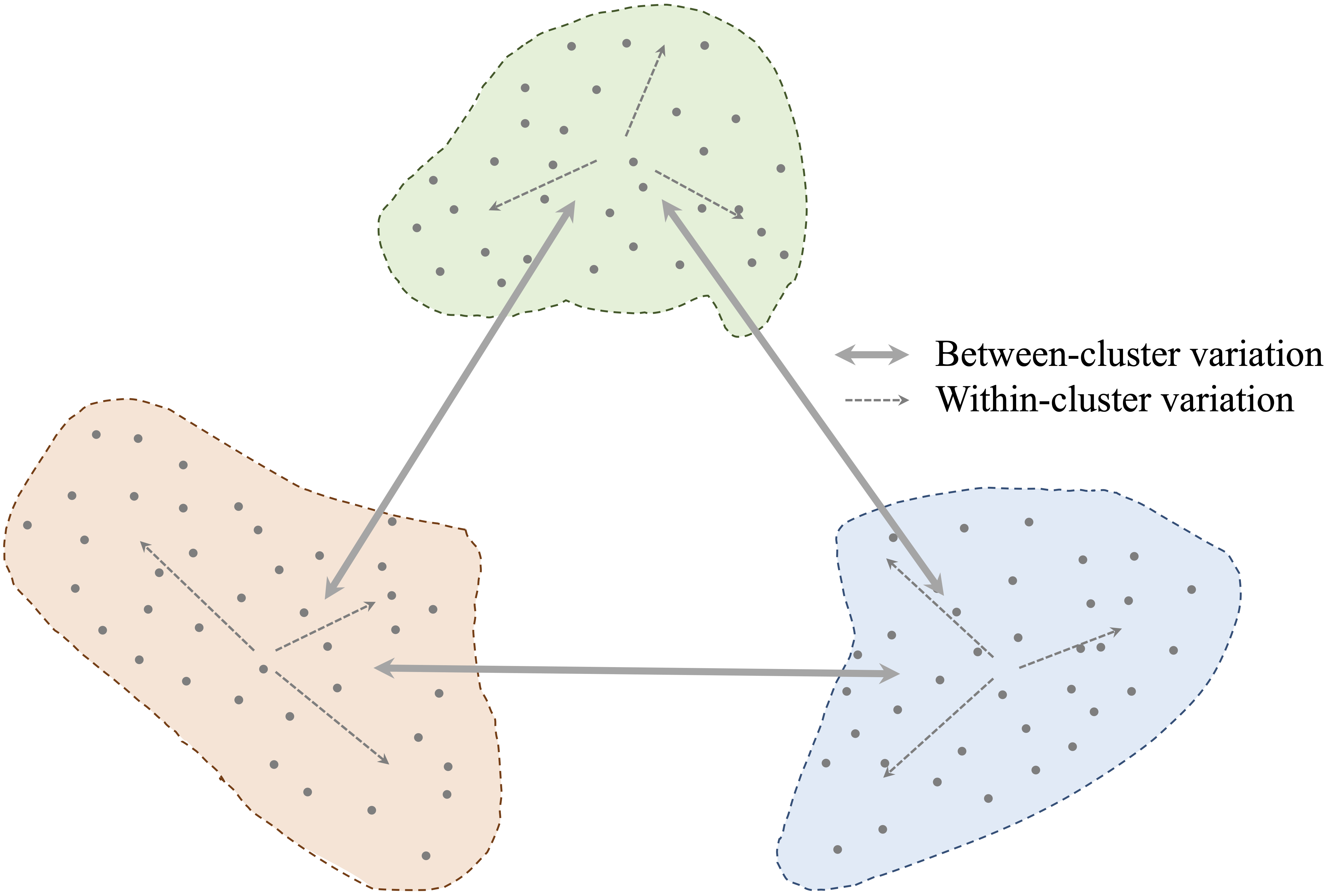
Figure 13.1: Clustering algorithms aim to minimize intra-cluster variation while maximizing inter-cluster separation.
Beyond its role in data exploration, clustering is widely used as a preprocessing step in machine learning. Given the massive scale of modern datasets, clustering helps reduce complexity by identifying a smaller number of representative groups, leading to several benefits:
-
Reduced computation time for downstream models.
-
Improved interpretability by summarizing large datasets.
- Enhanced predictive performance by structuring inputs for supervised learning.
In the following sections, we will explore K-means clustering, one of the most widely used clustering algorithms. We will also discuss methods for selecting the optimal number of clusters and apply clustering to a real-world dataset.
13.2 K-means Clustering
K-means clustering is one of the simplest and most widely used clustering algorithms. It aims to partition a dataset into \(k\) clusters by iteratively refining cluster centers, ensuring that data points within each cluster are as similar as possible. The algorithm operates through an iterative process of assigning points to clusters and updating cluster centers based on those assignments. The process stops when the assignments stabilize, meaning no data points switch clusters.
The K-means algorithm requires the user to specify the number of clusters, \(k\), in advance. It follows these steps:
-
Initialize: Randomly select \(k\) data points as the initial cluster centers.
-
Assignment: Assign each data point to the nearest cluster center. This creates \(k\) groups.
-
Update: Compute the centroid (mean) of each cluster and move the cluster centers to these new locations.
- Repeat: Iterate steps 2 and 3 until convergence—when cluster assignments no longer change.
Although K-means is simple and efficient, it has some limitations. The final clusters depend heavily on the initial choice of cluster centers, meaning different runs of the algorithm may produce different results. Additionally, K-means is sensitive to outliers and assumes clusters are spherical and of similar size, which may not always be the case in real-world data.
To illustrate how K-means works, consider a dataset with 50 records and two features, \(x_1\) and \(x_2\), as shown in Figure 13.2. Our goal is to partition the data into three clusters.
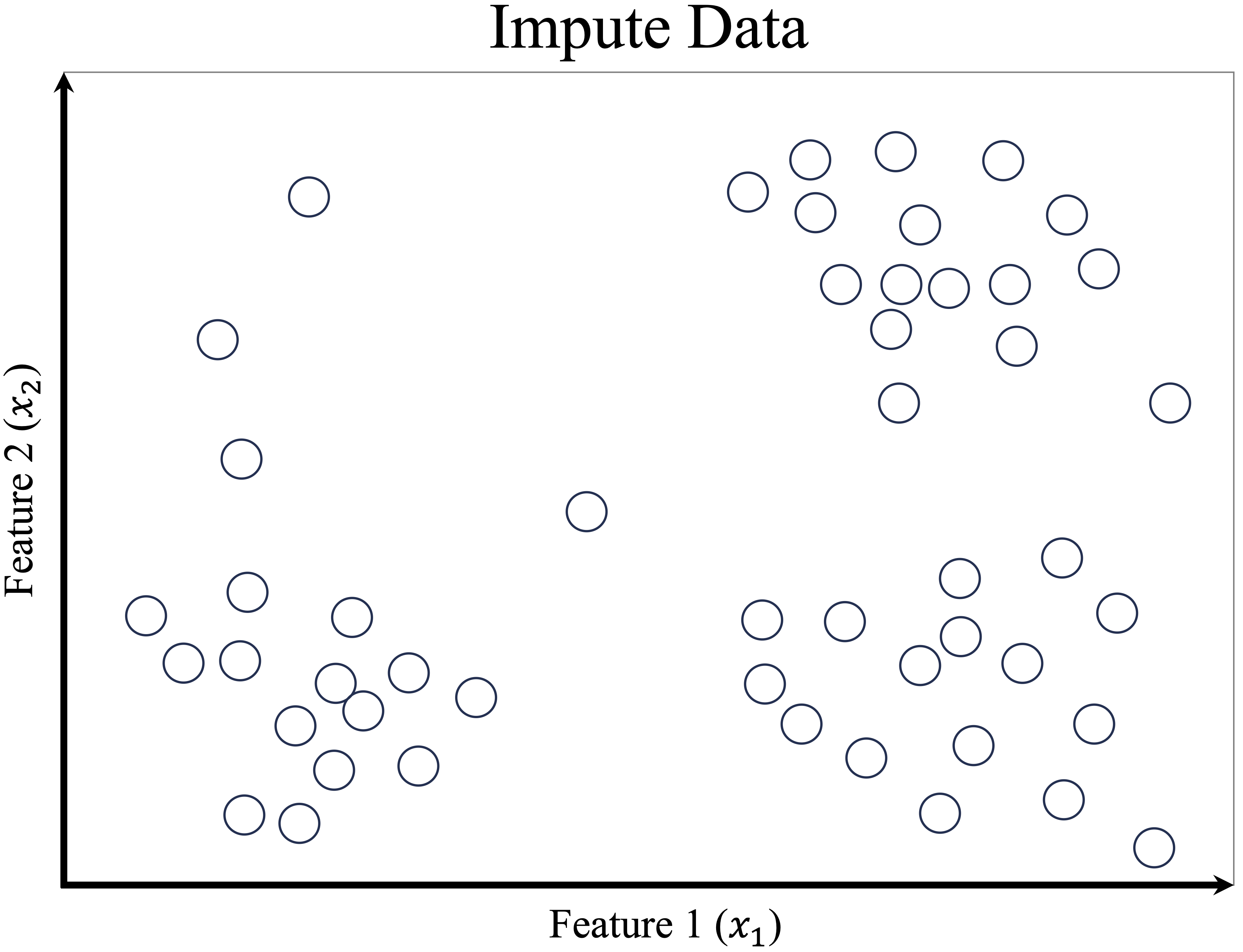
Figure 13.2: A simple dataset with 50 records and two features, ready for clustering.
The first step is to randomly select three initial cluster centers (red stars), as shown in the left panel of Figure 13.3. Each data point is then assigned to the nearest cluster, forming three groups labeled in blue (Cluster A), green (Cluster B), and orange (Cluster C). The right panel of Figure 13.3 displays these initial assignments. The dashed lines represent the Voronoi diagram, which divides space into regions associated with each cluster center.
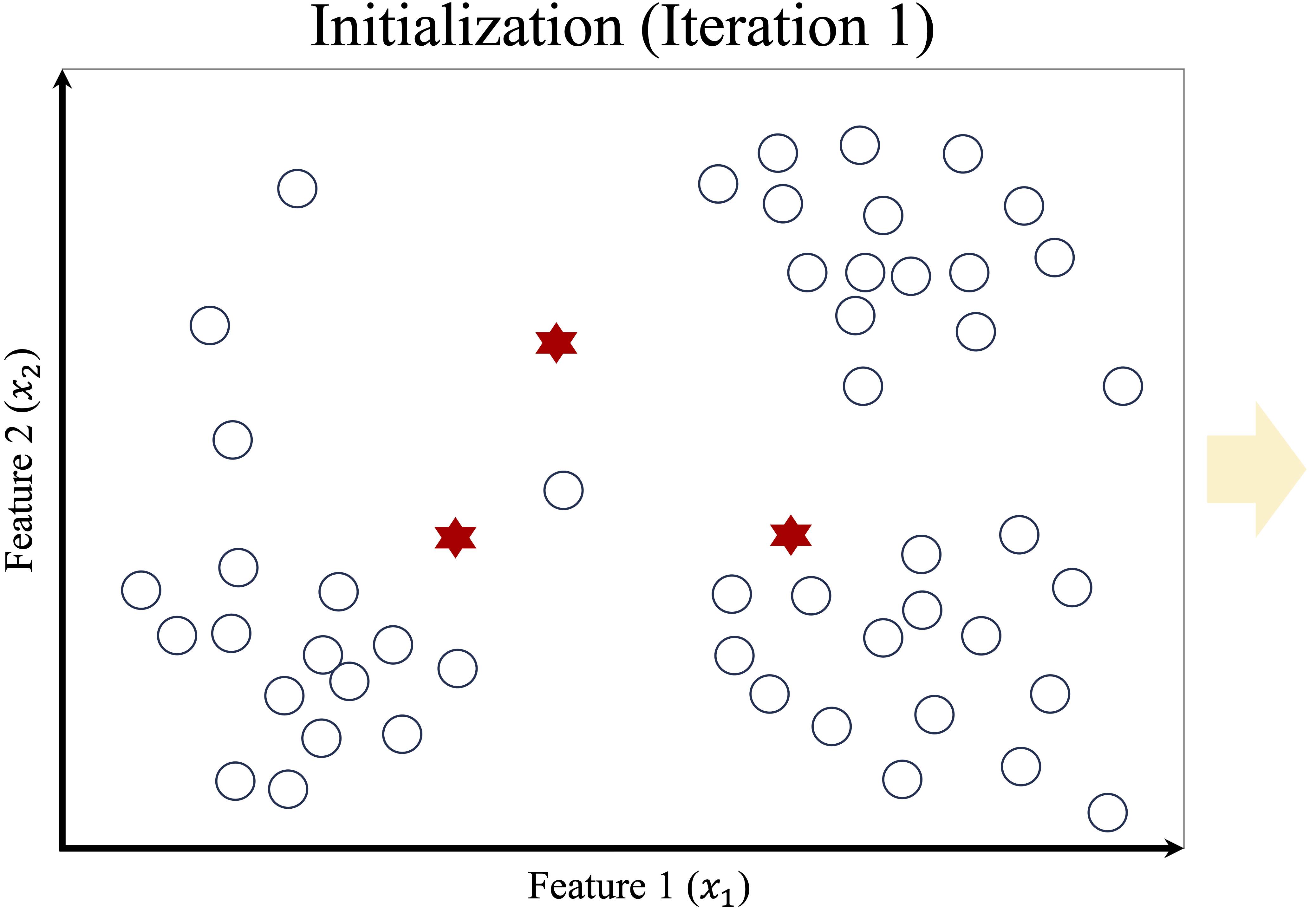
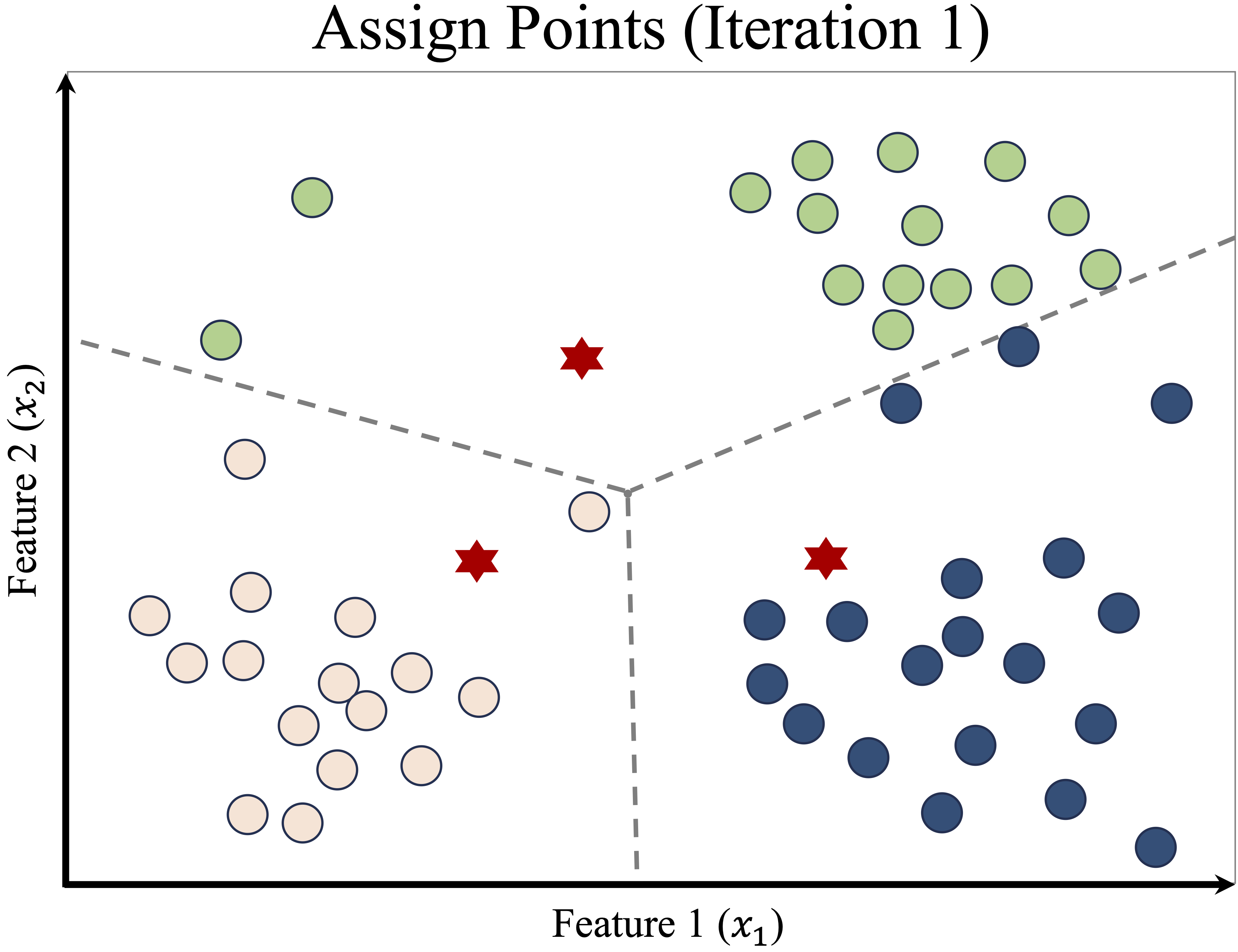
Figure 13.3: Initial random cluster centers (left) and first cluster assignments (right).
Since K-means is sensitive to initialization, poor placement of initial cluster centers can lead to suboptimal clustering. To mitigate this issue, K-means++13 was introduced in 2007. This method strategically selects initial centers to improve convergence and reduce randomness.
Once the initial cluster assignments are made, K-means enters the update phase. The first step is to recompute the centroid of each cluster, which is the mean position of all points assigned to that cluster. The cluster centers are then moved to these new centroid locations, as shown in the left panel of Figure 13.4. The right panel illustrates how the Voronoi boundaries shift, causing some data points to be reassigned to a different cluster.
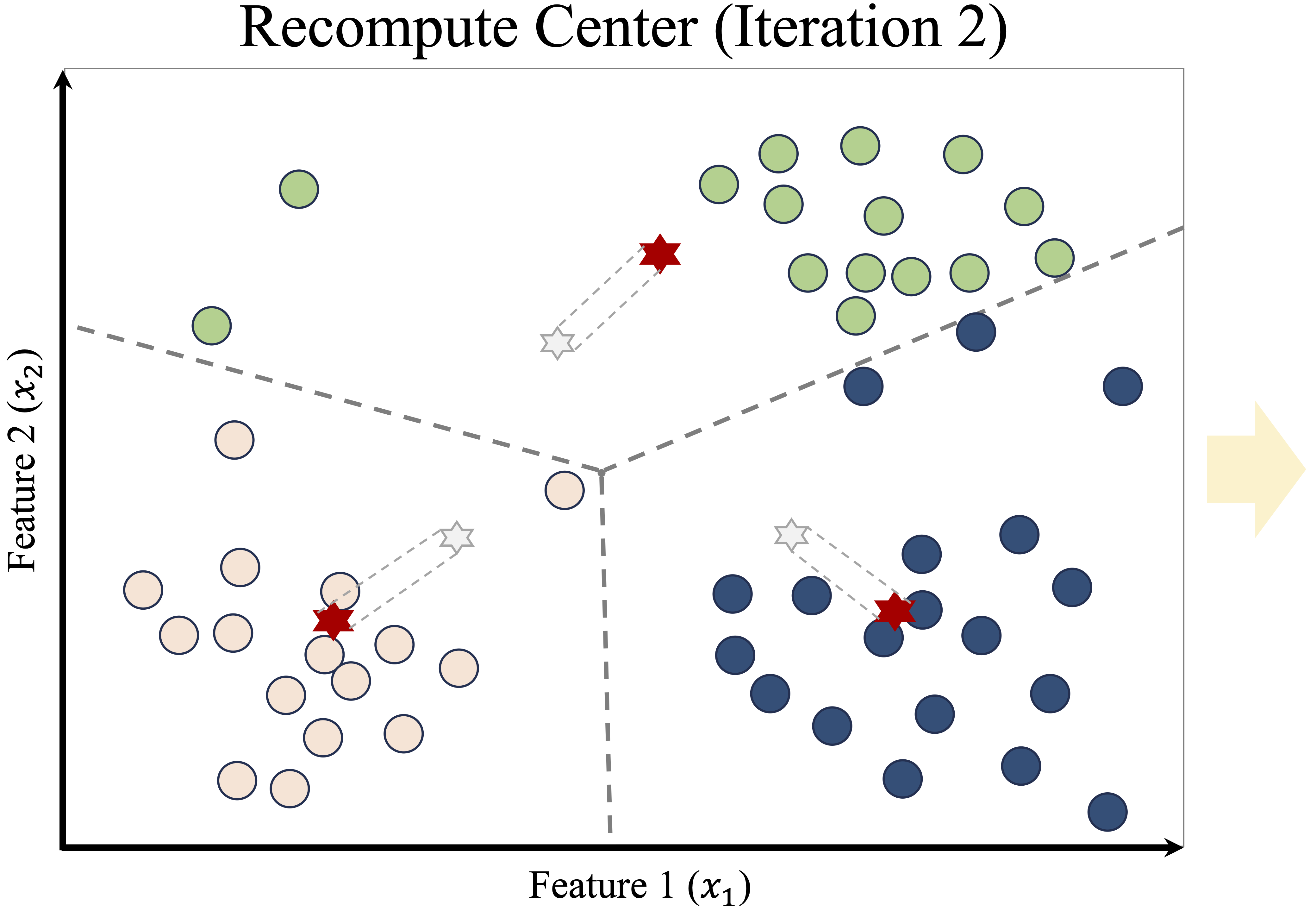
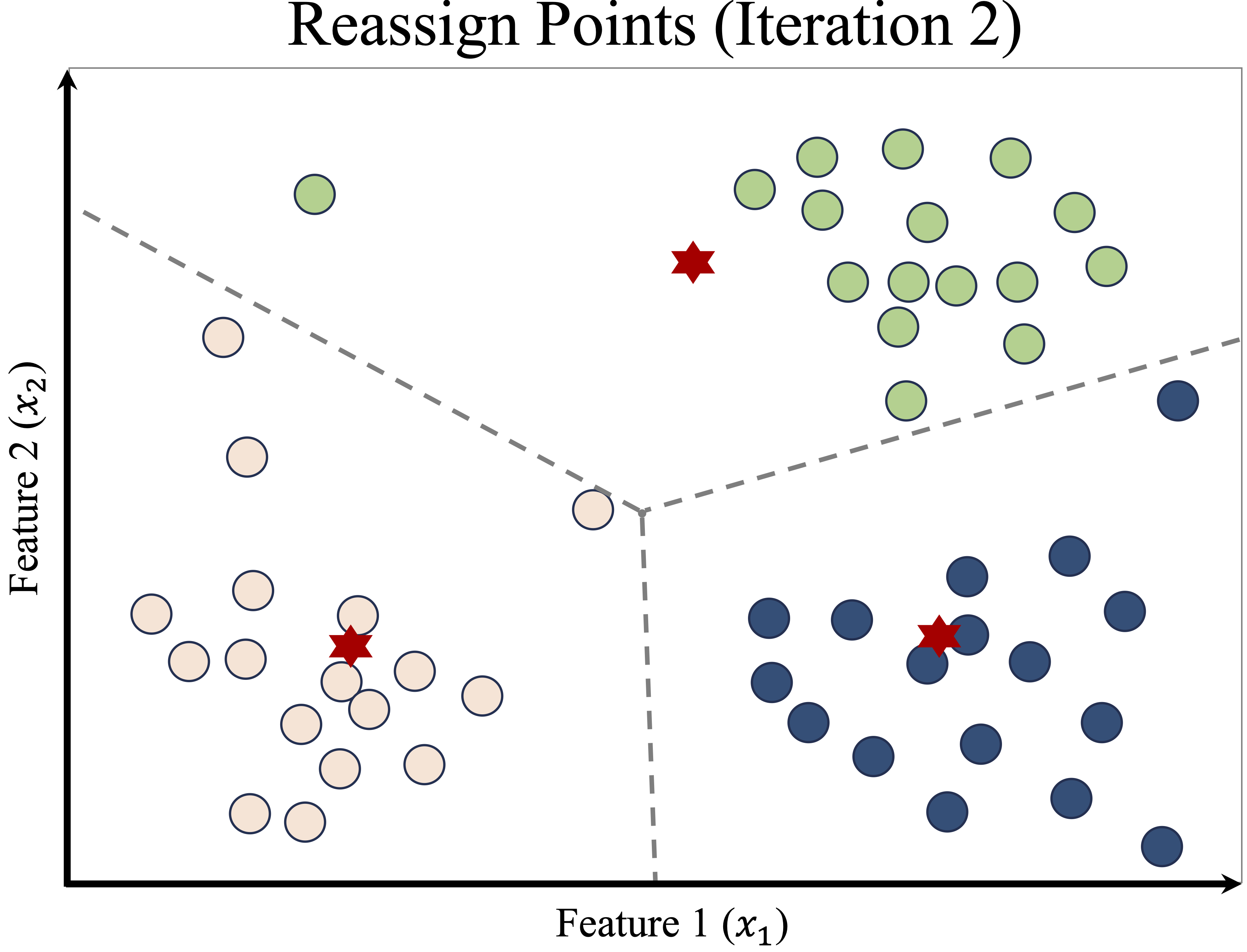
Figure 13.4: Updated cluster centers (left) and new assignments after centroid adjustment (right).
This process—reassigning points and updating centroids—continues iteratively. After another update, some points switch clusters again, leading to a refined Voronoi partition, as shown in Figure 13.5.
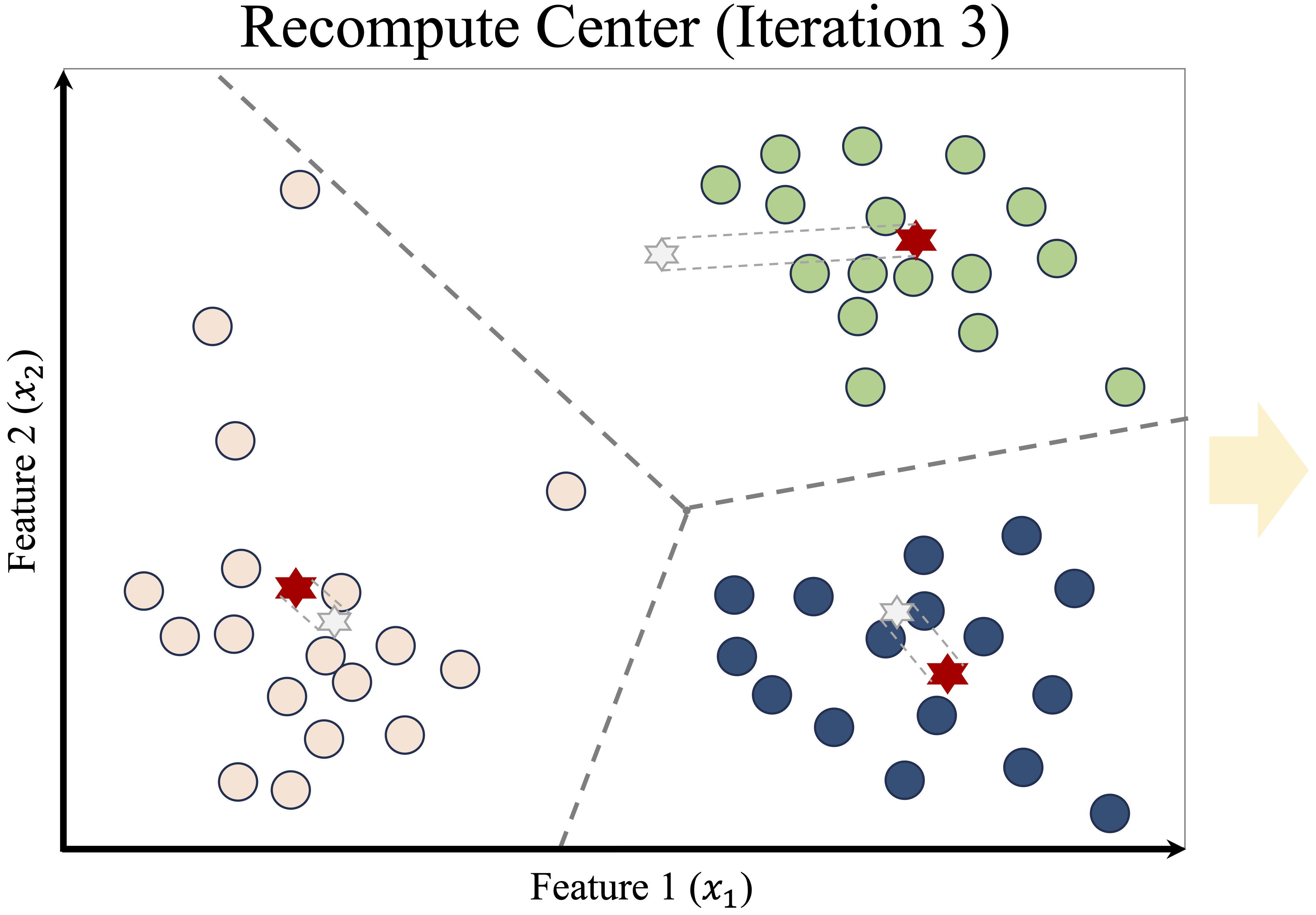
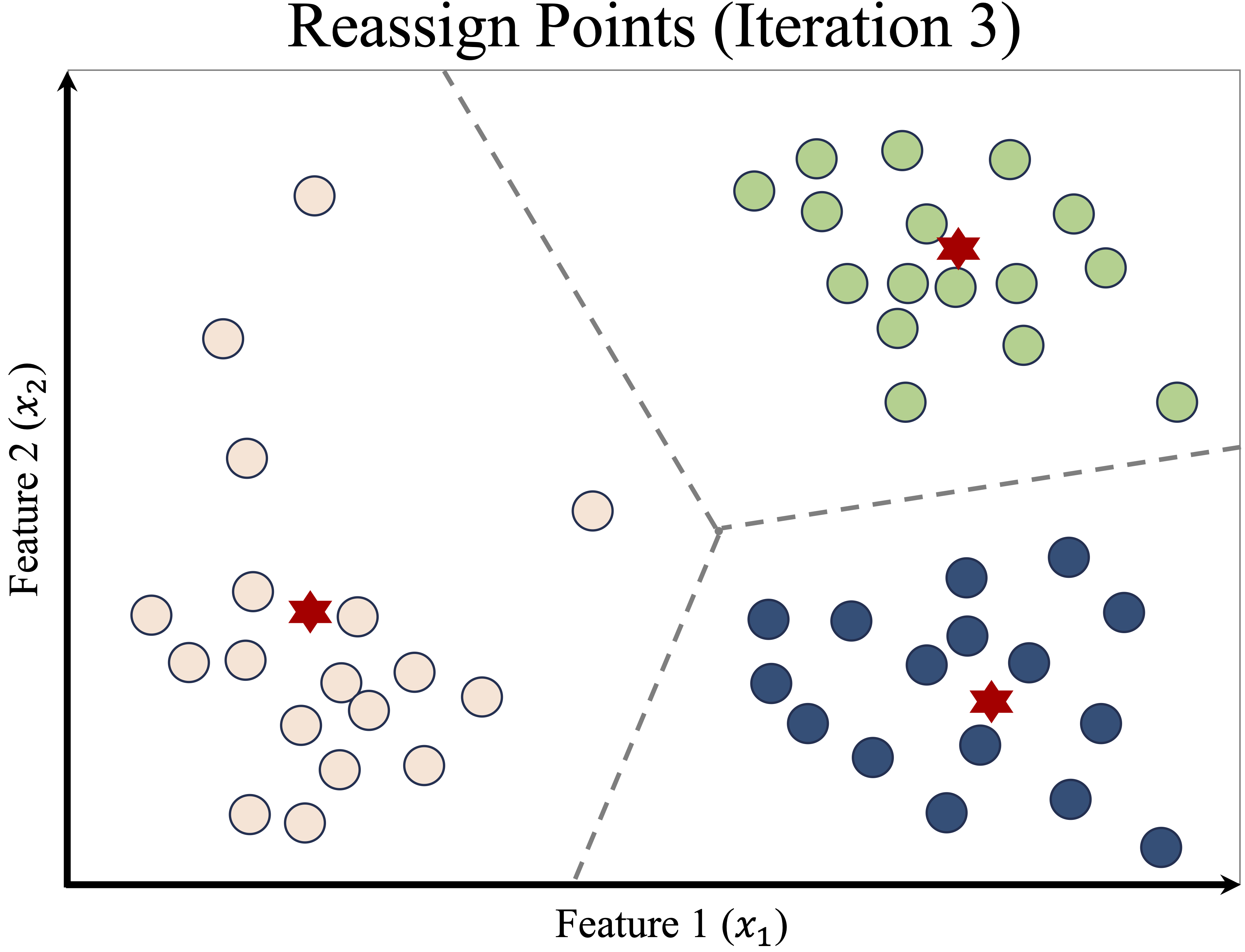
Figure 13.5: Updated cluster centers and assignments after another iteration.
The algorithm continues iterating until the cluster assignments stabilize—when no more points switch clusters, as shown in Figure 13.6. At this point, the algorithm converges, and the final clusters are established.
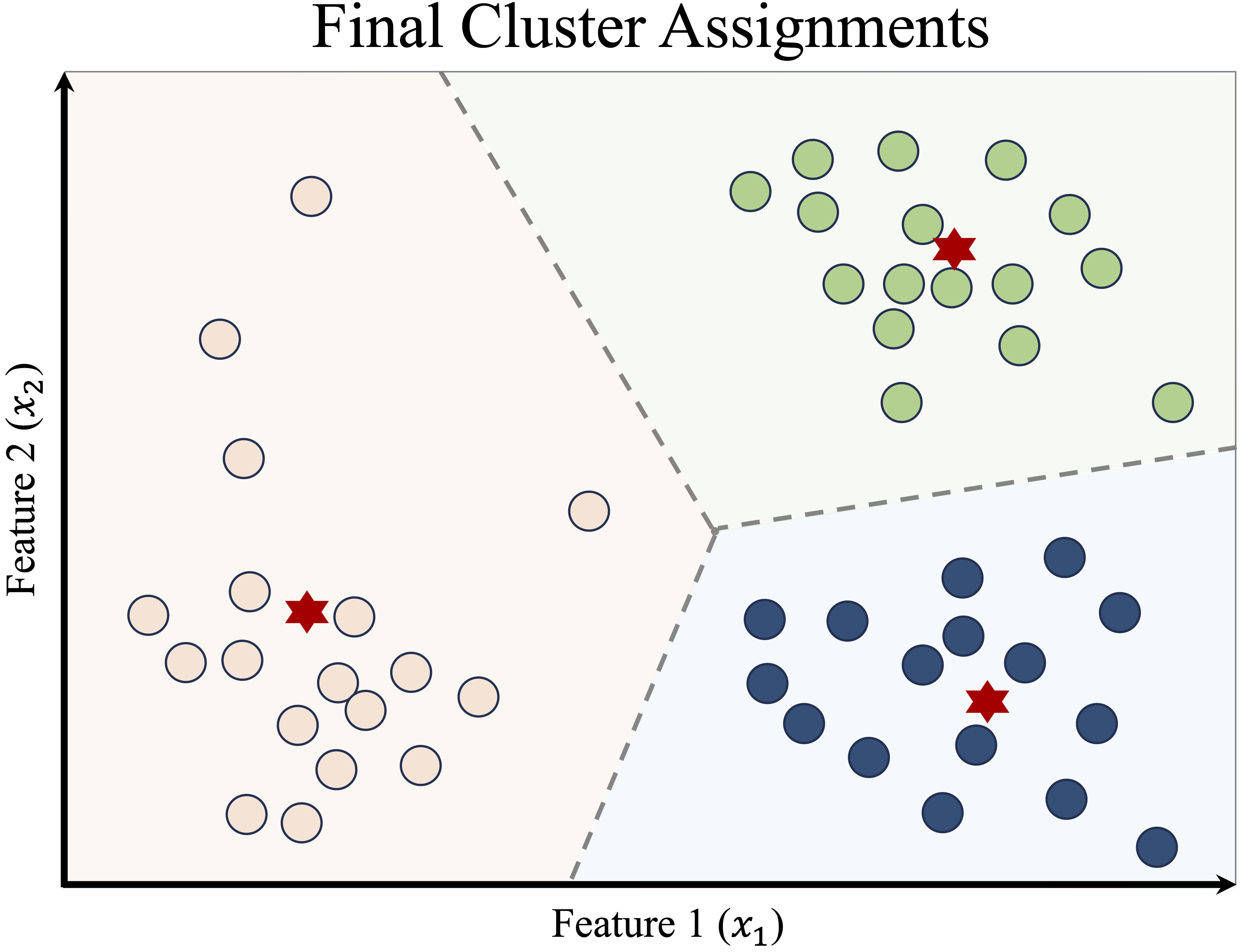
Figure 13.6: Final cluster assignments after K-means convergence.
Once clustering is complete, the results can be presented in two ways:
-
Cluster Assignments: Each data point is labeled as belonging to Cluster A, B, or C.
- Centroid Coordinates: The final positions of the cluster centers can be reported.
These final cluster centroids act as representative points, summarizing the dataset and enabling further analysis. K-means clustering is widely used in applications such as customer segmentation, image compression, and document clustering. In the next section, we will explore methods for selecting the optimal number of clusters to ensure meaningful partitions in real-world datasets.
13.3 Choosing the Number of Clusters
One of the key challenges in K-means clustering is selecting the appropriate number of clusters, \(k\). The choice of \(k\) significantly impacts the results—too few clusters may fail to capture meaningful structures, while too many clusters risk overfitting by creating overly fragmented groups. Unlike supervised learning, where evaluation metrics like accuracy guide model selection, clustering does not have an absolute ground truth, making the selection of \(k\) more subjective.
In some cases, domain knowledge can provide useful guidance. For example, when clustering movies, a reasonable starting point might be the number of well-known genres. In a business setting, marketing teams may set \(k = 3\) if they plan to design three distinct advertising campaigns. Similarly, seating arrangements at a conference might determine the number of groups based on the available tables. However, when no clear intuition exists, data-driven methods are needed to determine an optimal \(k\).
One widely used technique for choosing \(k\) is the elbow method, which evaluates how the within-cluster variation changes as the number of clusters increases. As more clusters are added, the clusters become more homogeneous (internal similarity increases), and overall heterogeneity (difference between clusters) decreases. However, this improvement follows a diminishing returns pattern. The idea is to find the point at which adding another cluster no longer significantly reduces the within-cluster variance.
This critical point, known as the elbow point, represents the most natural number of clusters. The concept is illustrated in Figure 13.7, where the curve shows the total within-cluster sum of squares (WCSS) as a function of \(k\). The “elbow” in the curve—where the rate of improvement slows—is a strong candidate for \(k\).
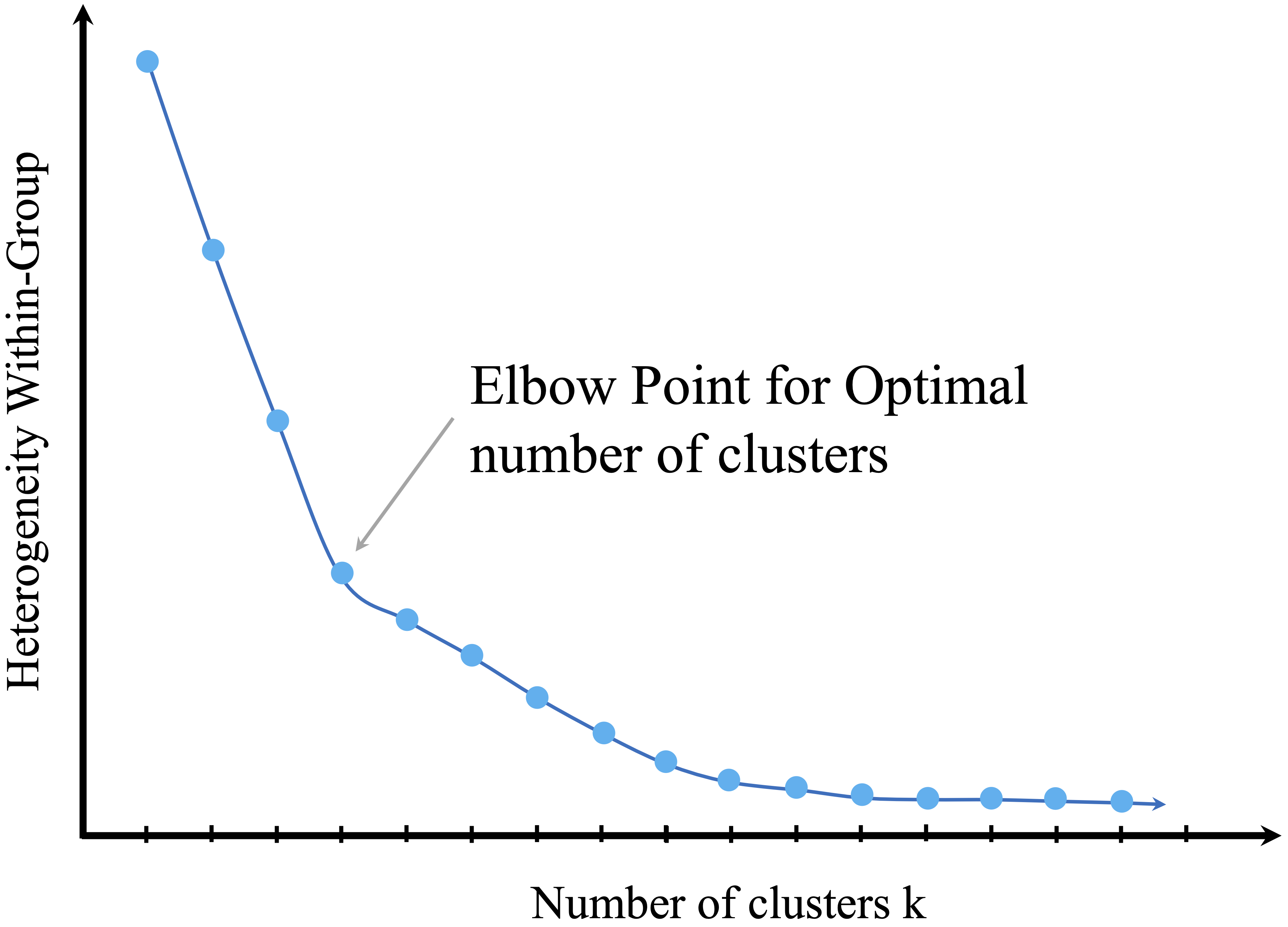
Figure 13.7: The elbow method helps determine the optimal number of clusters in K-means clustering.
While the elbow method provides a useful heuristic, it has limitations. In some datasets, the curve may not exhibit a clear elbow, making the choice of \(k\) more ambiguous. Additionally, evaluating many different values of \(k\) can be computationally expensive, especially for large datasets.
Other techniques can supplement or refine the selection of \(k\):
-
Silhouette Score: Measures how well each point fits within its assigned cluster compared to others. A higher silhouette score suggests a well-defined clustering structure.
-
Gap Statistic: Compares the clustering result with a reference distribution to assess whether the structure is significant.
- Cross-validation with clustering tasks: In applications where clustering feeds into a downstream task (e.g., classification), the impact of different \(k\) values can be evaluated in that context.
Ultimately, the choice of \(k\) should be driven by both data characteristics and practical considerations. Clustering is often used for exploratory analysis, meaning that the most useful \(k\) is not necessarily the mathematically “optimal” one but rather the one that yields meaningful, interpretable insights.
Observing how cluster characteristics evolve as \(k\) varies can itself be informative. Some groups may remain stable across different \(k\) values, indicating strong natural boundaries, while others may appear and disappear, suggesting more fluid structures in the data.
Rather than aiming for a perfect cluster count, it is often sufficient to find a reasonable and interpretable clustering solution. In the next section, we will apply clustering to a real-world dataset, demonstrating how practical knowledge can guide the choice of \(k\) for actionable insights.
Now that we have explored K-means clustering and methods for selecting the optimal number of clusters, we apply these concepts to a real-world dataset.
13.4 Case Study: Clustering Cereal Data
In this case study, we apply K-means clustering to the cereal dataset from the liver package. This dataset contains nutritional information for 77 cereal brands, including calories, protein, fat, sodium, fiber, and sugar content. Understanding these nutritional profiles is valuable for marketing strategies, consumer targeting, and product positioning. Our goal is to segment cereals into distinct groups based on their nutritional similarities.
13.4.1 Dataset Overview
The cereal dataset includes 77 observations and 16 variables, covering various nutritional attributes. It can be accessed through the liver package, as shown below:
We can examine its structure using:
str(cereal)
'data.frame': 77 obs. of 16 variables:
$ name : Factor w/ 77 levels "100% Bran","100% Natural Bran",..: 1 2 3 4 5 6 7 8 9 10 ...
$ manuf : Factor w/ 7 levels "A","G","K","N",..: 4 6 3 3 7 2 3 2 7 5 ...
$ type : Factor w/ 2 levels "cold","hot": 1 1 1 1 1 1 1 1 1 1 ...
$ calories: int 70 120 70 50 110 110 110 130 90 90 ...
$ protein : int 4 3 4 4 2 2 2 3 2 3 ...
$ fat : int 1 5 1 0 2 2 0 2 1 0 ...
$ sodium : int 130 15 260 140 200 180 125 210 200 210 ...
$ fiber : num 10 2 9 14 1 1.5 1 2 4 5 ...
$ carbo : num 5 8 7 8 14 10.5 11 18 15 13 ...
$ sugars : int 6 8 5 0 8 10 14 8 6 5 ...
$ potass : int 280 135 320 330 -1 70 30 100 125 190 ...
$ vitamins: int 25 0 25 25 25 25 25 25 25 25 ...
$ shelf : int 3 3 3 3 3 1 2 3 1 3 ...
$ weight : num 1 1 1 1 1 1 1 1.33 1 1 ...
$ cups : num 0.33 1 0.33 0.5 0.75 0.75 1 0.75 0.67 0.67 ...
$ rating : num 68.4 34 59.4 93.7 34.4 ...The dataset contains the following variables:
-
name: Name of the cereal (categorical).
-
manuf: Manufacturer of the cereal (categorical).
-
type: Cereal type (hot or cold, categorical).
-
calories: Calories per serving (numerical).
-
protein: Grams of protein per serving (numerical).
-
fat: Grams of fat per serving (numerical).
-
sodium: Milligrams of sodium per serving (numerical).
-
fiber: Grams of dietary fiber per serving (numerical).
-
carbo: Grams of carbohydrates per serving (numerical).
-
sugars: Grams of sugar per serving (numerical).
-
potass: Milligrams of potassium per serving (numerical).
-
vitamins: Percentage of FDA-recommended vitamins (categorical: 0, 25, or 100).
-
shelf: Display shelf position (categorical: 1, 2, or 3).
-
weight: Weight of one serving in ounces (numerical).
-
cups: Number of cups per serving (numerical).
-
rating: Cereal rating score (numerical).
13.4.2 Data Preprocessing
Before applying K-means clustering, we need to clean and preprocess the data. We start by summarizing the dataset:
summary(cereal)
name manuf type calories
100% Bran : 1 A: 1 cold:74 Min. : 50.0
100% Natural Bran : 1 G:22 hot : 3 1st Qu.:100.0
All-Bran : 1 K:23 Median :110.0
All-Bran with Extra Fiber: 1 N: 6 Mean :106.9
Almond Delight : 1 P: 9 3rd Qu.:110.0
Apple Cinnamon Cheerios : 1 Q: 8 Max. :160.0
(Other) :71 R: 8
protein fat sodium fiber
Min. :1.000 Min. :0.000 Min. : 0.0 Min. : 0.000
1st Qu.:2.000 1st Qu.:0.000 1st Qu.:130.0 1st Qu.: 1.000
Median :3.000 Median :1.000 Median :180.0 Median : 2.000
Mean :2.545 Mean :1.013 Mean :159.7 Mean : 2.152
3rd Qu.:3.000 3rd Qu.:2.000 3rd Qu.:210.0 3rd Qu.: 3.000
Max. :6.000 Max. :5.000 Max. :320.0 Max. :14.000
carbo sugars potass vitamins
Min. :-1.0 Min. :-1.000 Min. : -1.00 Min. : 0.00
1st Qu.:12.0 1st Qu.: 3.000 1st Qu.: 40.00 1st Qu.: 25.00
Median :14.0 Median : 7.000 Median : 90.00 Median : 25.00
Mean :14.6 Mean : 6.922 Mean : 96.08 Mean : 28.25
3rd Qu.:17.0 3rd Qu.:11.000 3rd Qu.:120.00 3rd Qu.: 25.00
Max. :23.0 Max. :15.000 Max. :330.00 Max. :100.00
shelf weight cups rating
Min. :1.000 Min. :0.50 Min. :0.250 Min. :18.04
1st Qu.:1.000 1st Qu.:1.00 1st Qu.:0.670 1st Qu.:33.17
Median :2.000 Median :1.00 Median :0.750 Median :40.40
Mean :2.208 Mean :1.03 Mean :0.821 Mean :42.67
3rd Qu.:3.000 3rd Qu.:1.00 3rd Qu.:1.000 3rd Qu.:50.83
Max. :3.000 Max. :1.50 Max. :1.500 Max. :93.70
Upon inspection, we notice unusual values in the variables sugars, carbo, and potass, where some entries are set to -1. Since negative values are invalid for these nutritional attributes, we replace them with NA:
cereal[cereal == -1] <- NA
find.na(cereal) # Check missing values
row col
[1,] 58 9
[2,] 58 10
[3,] 5 11
[4,] 21 11Next, we handle missing values using K-nearest neighbors (KNN) imputation with the knnImputation() function from the DMwR2 package:
library(DMwR2)
cereal <- knnImputation(cereal, k = 3, scale = TRUE)
find.na(cereal) # Verify missing values are filled
[1] " No missing values (NA) in the dataset."For clustering, we exclude categorical and identifier variables (name, manuf, and rating), retaining only numerical features:
Since the dataset includes features on different scales, we apply min-max scaling using the minmax() function from the liver package to ensure all variables contribute equally to the clustering process:
cereal_mm <- minmax(cereal_subset, col = "all")
str(cereal_mm) # Check the transformed dataset
'data.frame': 77 obs. of 13 variables:
$ type : num 0 0 0 0 0 0 0 0 0 0 ...
$ calories: num 0.182 0.636 0.182 0 0.545 ...
$ protein : num 0.6 0.4 0.6 0.6 0.2 0.2 0.2 0.4 0.2 0.4 ...
$ fat : num 0.2 1 0.2 0 0.4 0.4 0 0.4 0.2 0 ...
$ sodium : num 0.4062 0.0469 0.8125 0.4375 0.625 ...
$ fiber : num 0.7143 0.1429 0.6429 1 0.0714 ...
$ carbo : num 0 0.167 0.111 0.167 0.5 ...
$ sugars : num 0.4 0.533 0.333 0 0.533 ...
$ potass : num 0.841 0.381 0.968 1 0.122 ...
$ vitamins: num 0.25 0 0.25 0.25 0.25 0.25 0.25 0.25 0.25 0.25 ...
$ shelf : num 1 1 1 1 1 0 0.5 1 0 1 ...
$ weight : num 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.83 0.5 0.5 ...
$ cups : num 0.064 0.6 0.064 0.2 0.4 0.4 0.6 0.4 0.336 0.336 ...To visualize the effect of normalization, we plot the sodium distribution before and after scaling:
ggplot(data = cereal) +
geom_histogram(aes(x = sodium), color = "blue", fill = "lightblue") +
theme_minimal() + ggtitle("Before min-max normalization")
ggplot(data = cereal_mm) +
geom_histogram(aes(x = sodium), color = "blue", fill = "lightblue") +
theme_minimal() + ggtitle("After min-max normalization")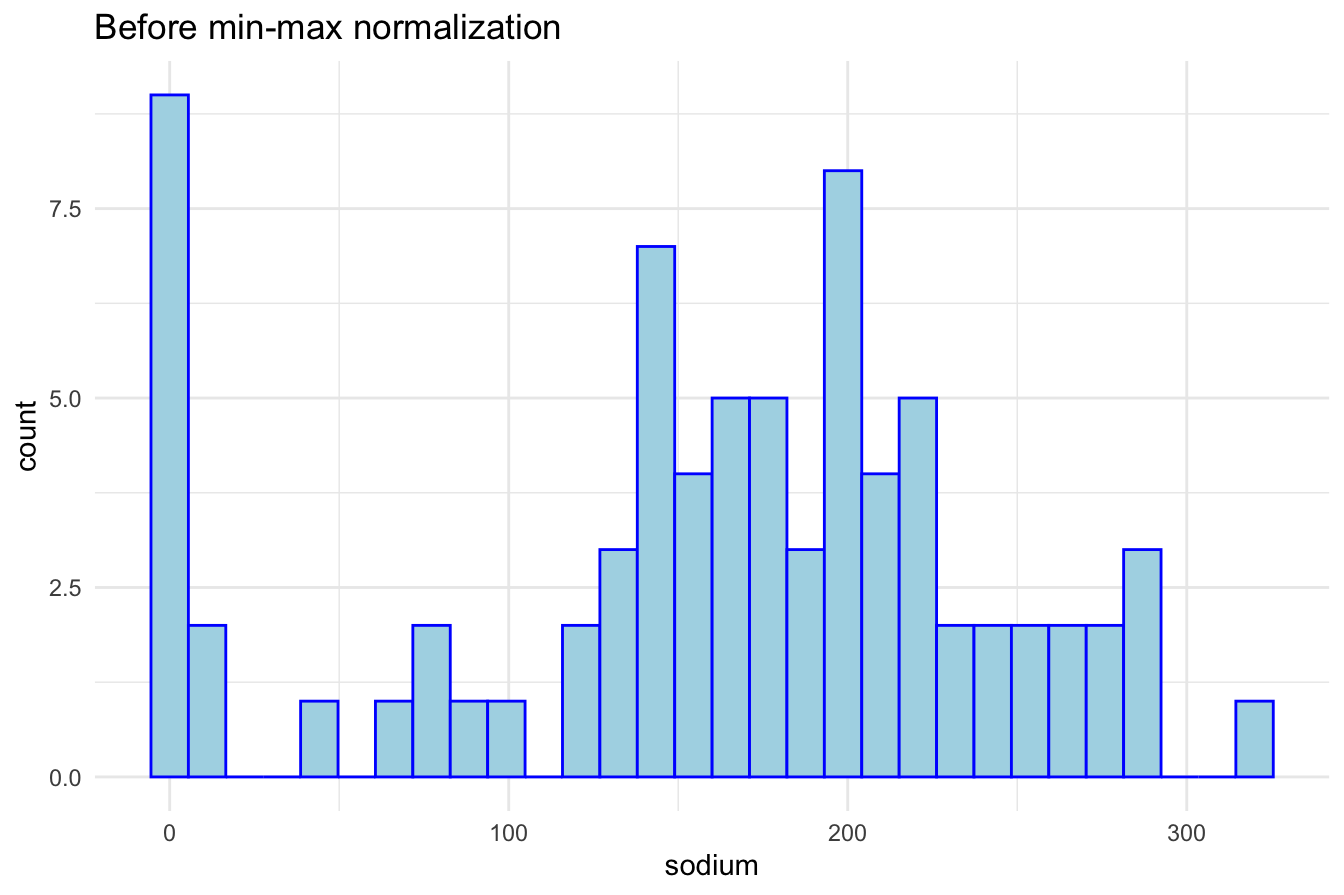
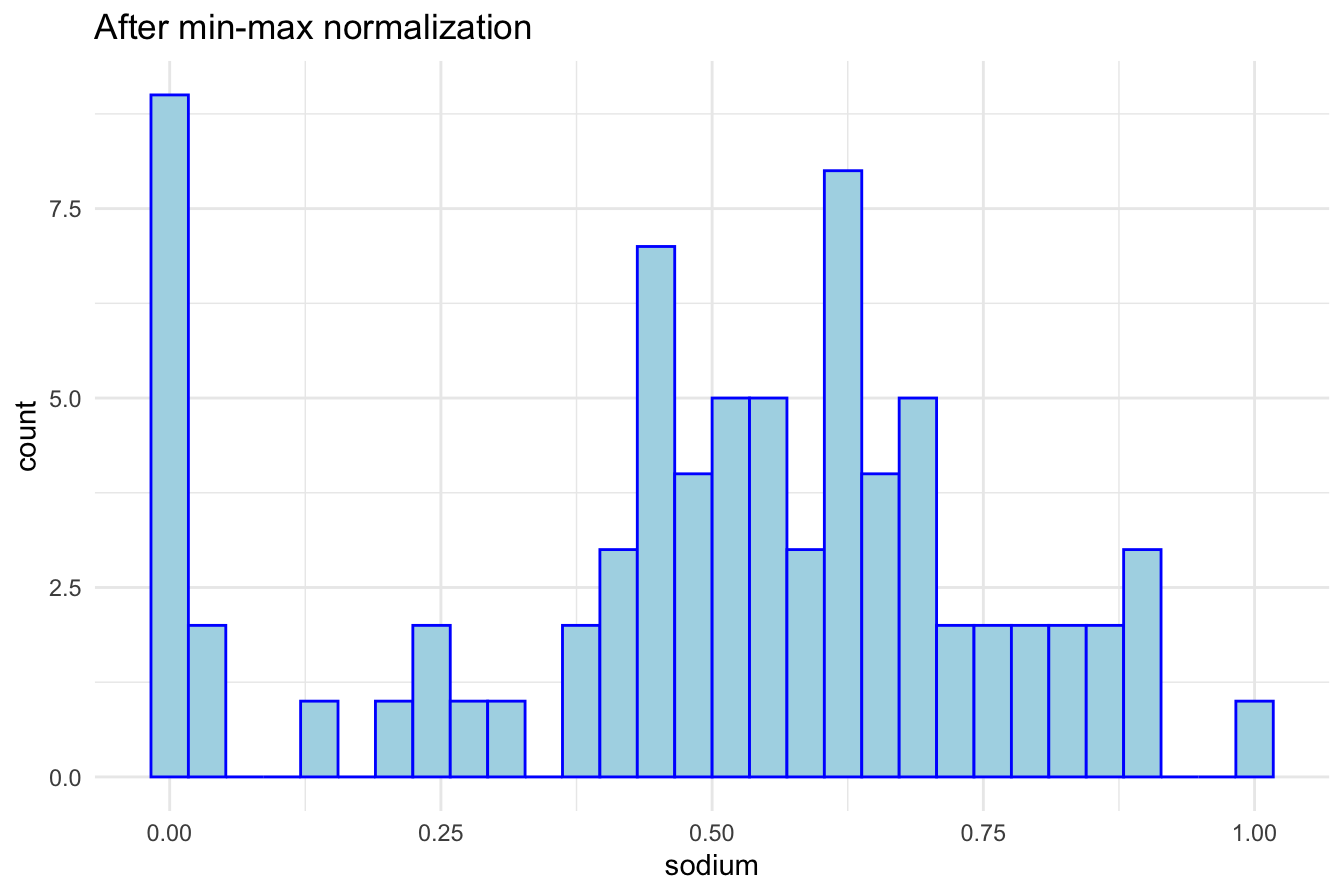
After scaling, all values fall within the 0–1 range, making distance-based clustering more reliable.
13.4.3 Applying K-means Clustering
Choosing the Optimal Number of Clusters
Before clustering, we need to determine the optimal number of clusters. We use the elbow method, which plots the within-cluster sum of squares (WCSS) for different values of \(k\). The elbow point—where the improvement in WCSS slows—suggests an ideal \(k\):
library(factoextra)
fviz_nbclust(cereal_mm, kmeans, method = "wss", k.max = 15) +
geom_vline(xintercept = 4, linetype = 2, color = "gray")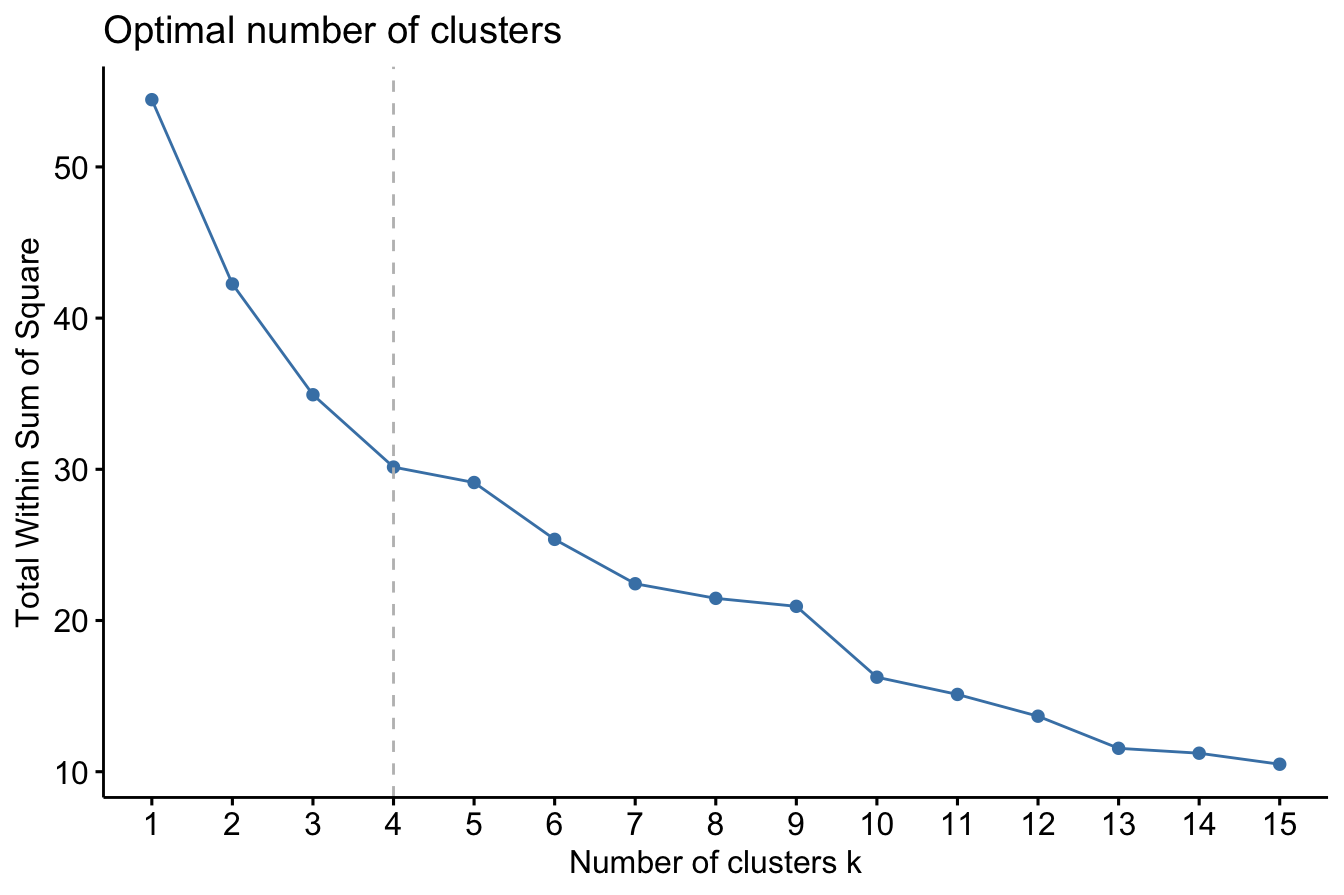
From the plot, we observe that \(k = 4\) clusters is a reasonable choice, as adding more clusters beyond this point yields diminishing improvements in WCSS.
Performing K-means Clustering
We now apply the K-means algorithm with \(k = 4\) clusters:
To check cluster sizes:
Visualizing the Clusters
To better understand the clustering results, we visualize the clusters using the fviz_cluster() function from the factoextra package:
fviz_cluster(cereal_kmeans, cereal_mm, geom = "point", ellipse.type = "norm", palette = "custom_palette")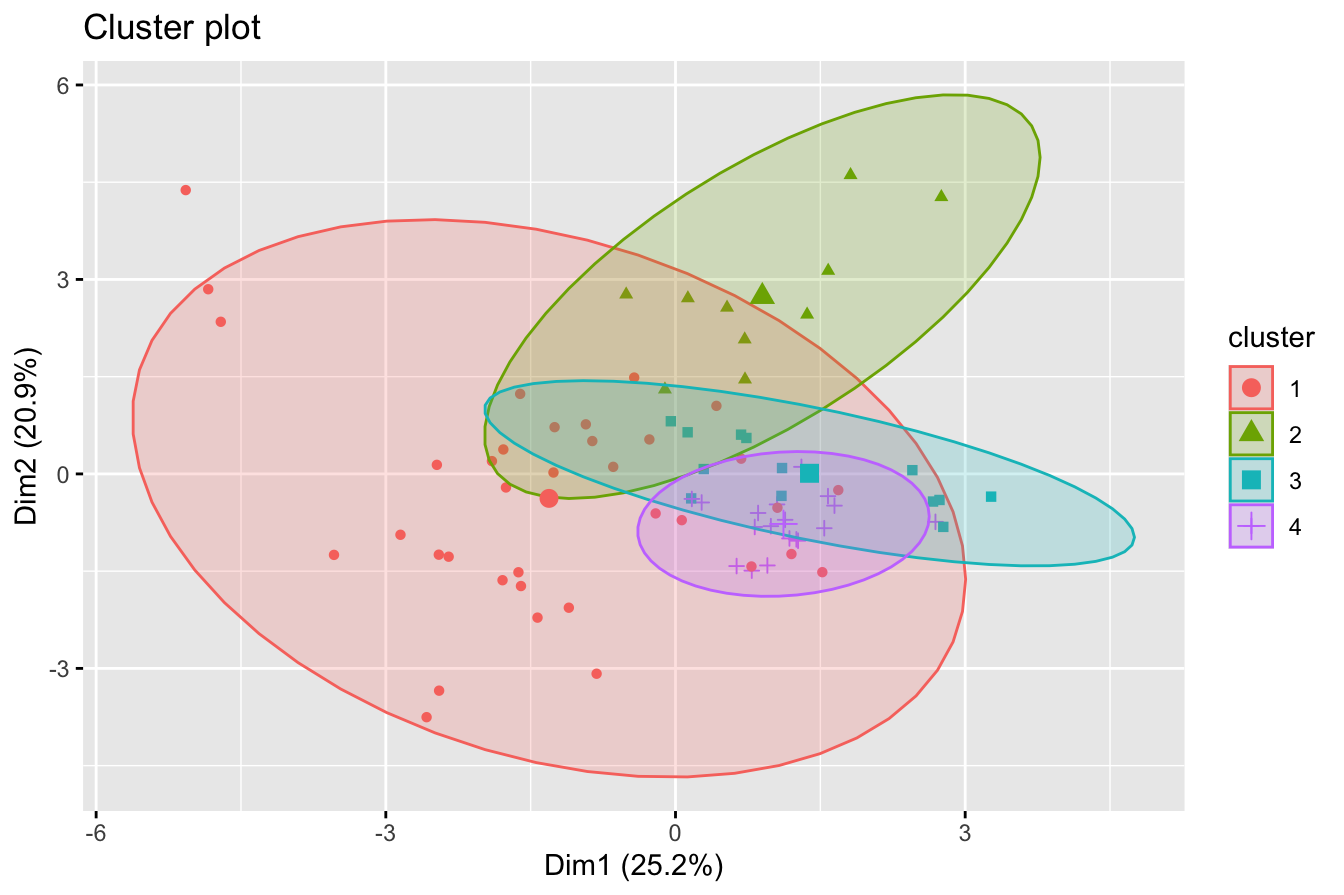
The scatter plot displays the four clusters, with each point representing a cereal brand. Different colors indicate distinct clusters, and the ellipses represent the spread of each cluster based on its standard deviation.
Interpreting the Results
The clusters reveal natural groupings among cereals based on nutritional content. For example:
- Some clusters may contain low-sugar, high-fiber cereals, appealing to health-conscious consumers.
- Others may group high-calorie, high-sugar cereals, often marketed to children.
- Another group may include balanced cereals, offering a mix of moderate calories and nutrients.
To examine which cereals belong to a specific cluster (e.g., Cluster 1), we can use:
cereal$name[cereal_kmeans$cluster == 1]This command lists the names of cereals assigned to Cluster 1, helping us interpret the characteristics of that group.
This case study demonstrated how K-means clustering can segment cereals into meaningful groups based on nutritional content. Through data preprocessing, feature scaling, and cluster visualization, we successfully grouped cereals with similar characteristics. Such clustering techniques are widely applicable in marketing, consumer analytics, and product positioning, providing actionable insights for businesses and researchers alike.
In this chapter, we explored the fundamentals of clustering, the mechanics of the K-means algorithm, and methods for choosing the optimal number of clusters. We then applied these concepts to a real-world dataset, demonstrating how K-means can extract meaningful insights. Clustering remains a powerful tool across various domains, from marketing to bioinformatics, making it an essential technique in the modern data science toolkit.
Exercises
These exercises reinforce the concepts introduced in this chapter, focusing on clustering fundamentals, hyperparameter tuning, and practical applications using the redWines dataset. The exercises are divided into two categories:
- Conceptual questions – Understanding the theory behind clustering and K-means.
- Practical exercises using the redWines dataset – Applying clustering techniques to real-world data.
Conceptual questions
- What is clustering, and how does it differ from classification?
- Explain the concept of similarity measures in clustering. What is the most commonly used distance metric for numerical data?
- Why is clustering considered an unsupervised learning method?
- What are some real-world applications of clustering? Name at least three.
- Define the terms intra-cluster similarity and inter-cluster separation. Why are these important in clustering?
- How does K-means clustering determine which data points belong to a cluster?
- Explain the role of centroids in K-means clustering.
- What happens if the number of clusters \(k\) in K-means is chosen too small? What if it is too large?
- What is the elbow method, and how does it help determine the optimal number of clusters?
- Why is K-means sensitive to the initial selection of cluster centers? How does K-means++ address this issue?
- Describe a scenario where Euclidean distance might not be an appropriate similarity measure for clustering.
- Why do we need to normalize or scale variables before applying K-means clustering?
- How does clustering help in dimensionality reduction and preprocessing for supervised learning?
- What are the key assumptions of K-means clustering?
- How does the silhouette score help evaluate the quality of clustering?
- Compare K-means with hierarchical clustering. What are the advantages and disadvantages of each?
- Why is K-means not suitable for non-spherical clusters?
- What is the difference between hard clustering (e.g., K-means) and soft clustering (e.g., Gaussian Mixture Models)?
- What are outliers, and how do they affect K-means clustering?
- What are alternative clustering methods that handle outliers better than K-means?
Practical exercises using the redWines dataset
The redWines dataset contains chemical properties of red wines and their quality scores. These exercises guide you through clustering analysis, from data preprocessing to model evaluation.
Data preparation and exploratory analysis
- Load the redWines dataset from the liver package and inspect its structure.
- Summarize the dataset using
summary(). Identify any missing values.
- Check the distribution of wine quality scores in the dataset. What is the most common wine quality score?
- Since clustering requires numerical features, remove any non-numeric columns from the dataset.
- Apply min-max scaling to normalize all numerical variables before clustering. Why is this step necessary?
Applying K-means clustering
- Use the elbow method to determine the optimal number of clusters for the dataset.
library(factoextra)
fviz_nbclust(redWines, kmeans, method = "wss")- Based on the elbow plot, choose an appropriate value of \(k\) and perform K-means clustering.
- Visualize the clusters using a scatter plot of two numerical features.
- Compute the silhouette score to evaluate cluster cohesion and separation.
- Identify the centroids of the final clusters and interpret their meaning.
Interpreting the clusters
- Assign the cluster labels to the original dataset and examine the average chemical composition of each cluster.
- Compare the wine quality scores across clusters. Do some clusters contain higher-quality wines than others?
- Identify which features contribute most to defining the clusters.
- Are certain wine types (e.g., high acidity, high alcohol content) concentrated in specific clusters?
- Experiment with different values of \(k\) and compare the clustering results. Does increasing or decreasing \(k\) improve the clustering?
- Visualize how wine acidity and alcohol content influence cluster formation.